Introduzione a Kubernetes
Learning Friday del 04/09/2020
Alessandro Accardo
Chi sono
Ciao, sono Alessandro Accardo, forse vi ricorderete di me per un Learning Friday su Docker.
Ecco chi sono.
- Senior Developer
- Solution Architect
- Specializzato in soluzioni Cloud-Native
- Nerd
- Appassionato di tecnologia
- Hacker
Cos'è Kubernetes
Kubernetes è un sistema di orchestrazione di container. Esaminiamo parola per parola.
Sistema
Spero sappiate cos'è un sistema, altrimenti ho pessime notizie…

Orchestrazione
Wikipedia dice questo in merito a cosa è l'orchestrazione di sistemi informatici:
In system administration, orchestration is the automated configuration, coordination, and management of computer systems and software. – Orchestration (computing)
Cioè, stiamo parlando di un sistema che è in grado di automatizzare le operazioni di configurazione, deploy e gestione di software, come dice wikipedia. Più in particolare, quando si parla di Kubernetes, i software sono container.
Container
Sapere cosa è un container è un prerequisito di questo Learning Friday, per dubbi andate allo scorso LF.
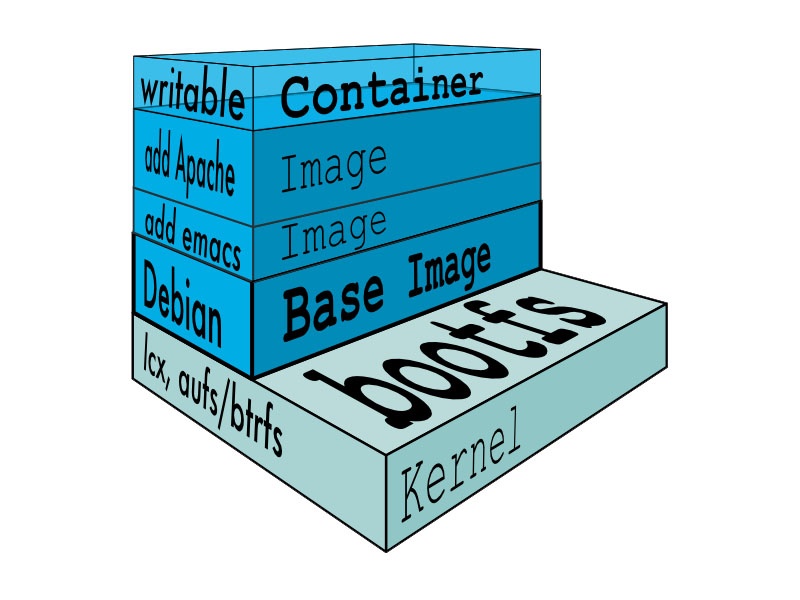
Perché li amiamo?
I container forniscono un meccanismo leggero per isolare l'ambiente di un'applicazione.
Per una data applicazione, possiamo specificare la configurazione del sistema e le librerie che vogliamo installare senza preoccuparci di creare conflitti con altre applicazioni che potrebbero essere in esecuzione sulla stessa macchina fisica.
Incapsuliamo ogni applicazione come un'immagine del container che può essere eseguita in modo affidabile su qualsiasi macchina, fornendoci la portabilità per consentire transizioni fluide dallo sviluppo alla distribuzione.
Inoltre, poiché ogni applicazione è autonoma senza la preoccupazione di conflitti ambientali, è più facile posizionare più carichi di lavoro sulla stessa macchina fisica e ottenere un maggiore utilizzo delle risorse (memoria e CPU), riducendo in definitiva i costi.
Cosa manca ai container quindi?
- Che succede se il tuo container muore?
- Che succede se la macchina che esegue il container muore? I container non forniscono una soluzione per la tolleranza agli errori.
- Se hai più container che devono comunicare tra loro o con il mondo esterno, come abiliti la rete tra i container?
- Come cambia la topologia di rete mentre accendi o spegni i container? Il networking dei container può facilmente diventare un guazzabuglio medievale (courtesy of Mago Merlino)
- Infine, supponiamo che il tuo ambiente di produzione sia composto da più macchine: come decidi quale macchina utilizzare per eseguire il container?
Si, ma perché Kubernetes?
La domanda più lecita che ci si potrebbe porre.
Abbiamo sistemi di controllo della configurazione come Ansible e Puppet, abbiamo software dinamici, abbiamo repository della configurazione, quindi perché?
Perché…
- Permette di gestire i container
- Permette di scalare i container
- Permette di configurate facilmente il networking dei container
- E una pletora di altre cose…
Architetture complesse
Kubernetes non è uno strumento da prendere alla leggera, e non serve di certo per mettere in piedi il prossimo blog con Wordpress.
Per alcuni sistemi complessi l'elaborazione viene spezzata in diversi software che svolgono ognuno una parte del calcolo.
Tutti questi processi possono essere gestiti da un processo principale che governa l'elaborazione, oppure possono autogestirsi comunicando tra loro per passare il calcolo al processo successivo.
Nel caso dell'elaborazione distribuita i programmi hanno bisogno di un ambiente operativo completo di networking che nel caso specifico viene implementato come un container.
Le architetture complesse hanno bisogno di soddisfare diversi requisiti di funzionamento e devono garantire un alto livello di sicurezza, uno dei tanti motivi per cui si usano i container.
I requisiti delle architetture complesse
Quindi, quali sono questi requisiti?
Tolleranza ai guasti
Chiaramente un sistema non deve interrompere il servizio in presenza di guasti, e per quanto possibile deve poterli gestire e riparare.
Sarebbe quanto meno ingenuo pensare che un sistema non dovrebbe avere guasti in primo luogo, i guasti esistono, i bug pure, e i pessimi programmatori anche, quindi un sistema ben progettato deve resistere a quello che io definisco come intemperie.
Scalabilità
Un sistema deve poter gestire il carico di lavoro, che ricade sempre nel principio di non interruzione del servizio.
Il carico è un elemento variabile (in alcuni casi, molto variabile) e questo presuppone che un software sia in grado di gestire qualsiasi quantitativo di richieste, giusto?
Sbagliato!
Un software viene progettato per poter gestire un determinato carico, compreso tra un minimo e un massimo, dove non necessariamente il minimo è zero. Quando si arriva al massimo, semplicemente il software interrompe il servizio e questo non è ammissibile.
Repliche
Il modo migliore da sempre per gestire il carico è il buon vecchio adagio divide et impera che in termini di software si traduce in:
Esegui una n-esima istanza del software e distribuisci il carico tra tutte le istanze, chiamate repliche.
Configurabilità
Ogni software ha bisogno di una configurazione, tutti i software di una certa complessità tendono a sviluppare una configurazione più o meno complessa.
Mantenere la configurazione di ogni software può diventare complicato quando i software sono tanti, soprattutto quando il tutto va fatto manualmente.
Automatismi
Tutto questo parlare di repliche con tutti questi requisiti porta a considerare la possibilità di automatizzare i processi di gestione delle repliche, delle configurazioni, dei log degli errori, della gestione della rete.
Altri requisiti
Ce ne sono molti altri, ma questi sono quelli che mi permettono di andare verso la soluzione.
Kubernetes to the rescue!
Kubernetes risolve i problemi di dinamicità di questo tipo di configurazioni complesse.
Una piattaforma di orchestrazione dei container gestisce l'intero ciclo di vita dei singoli container, attivando e disattivando le risorse secondo necessità.
Se un container muore inavvertitamente, la piattaforma di orchestrazione reagirà avviando un altro contenitore al suo posto.
Inoltre, la piattaforma di orchestrazione fornisce un meccanismo per la comunicazione tra le applicazioni anche quando i singoli contenitori sottostanti vengono creati e distrutti.
Ma come funziona Kubernetes? Di quali componenti è composto? Quali sono le sue funzionalità di base?
Princìpi di progettazione
Kubernetes è un sistema dichiarativo. Questo significa che l'intera installazione della piattaforma viene descritta da una serie di file di configurazione.
Questo concetto è fondamentale, per comprendere una delle funzioni di base di Kubernetes, la sua capacità di auto curarsi.
Tramite la configurazione si dichiara alla piattaforma qual è lo stato desiderato e Kubernetes si assicurerà che lo stato attuale sia esattamente come descritto nella configurazione, altrimenti ce lo porterà.
In questo modo di fatto Kubernetes saprà quando lo stato è differente dalla configurazione desiderata e sarà sempre in grado di curarsi da solo.
Un altro dei principi fondanti di Kubernetes è di essere distribuito.
Kubernetes è progettato per fornire il livello infrastrutturale per tali sistemi distribuiti, fornendo astrazioni pulite per creare applicazioni su una raccolta di macchine (note collettivamente come cluster).
Più specificamente, Kubernetes fornisce un'interfaccia unificata per interagire con questo cluster in modo tale da non doverti preoccupare di comunicare individualmente con ogni macchina.
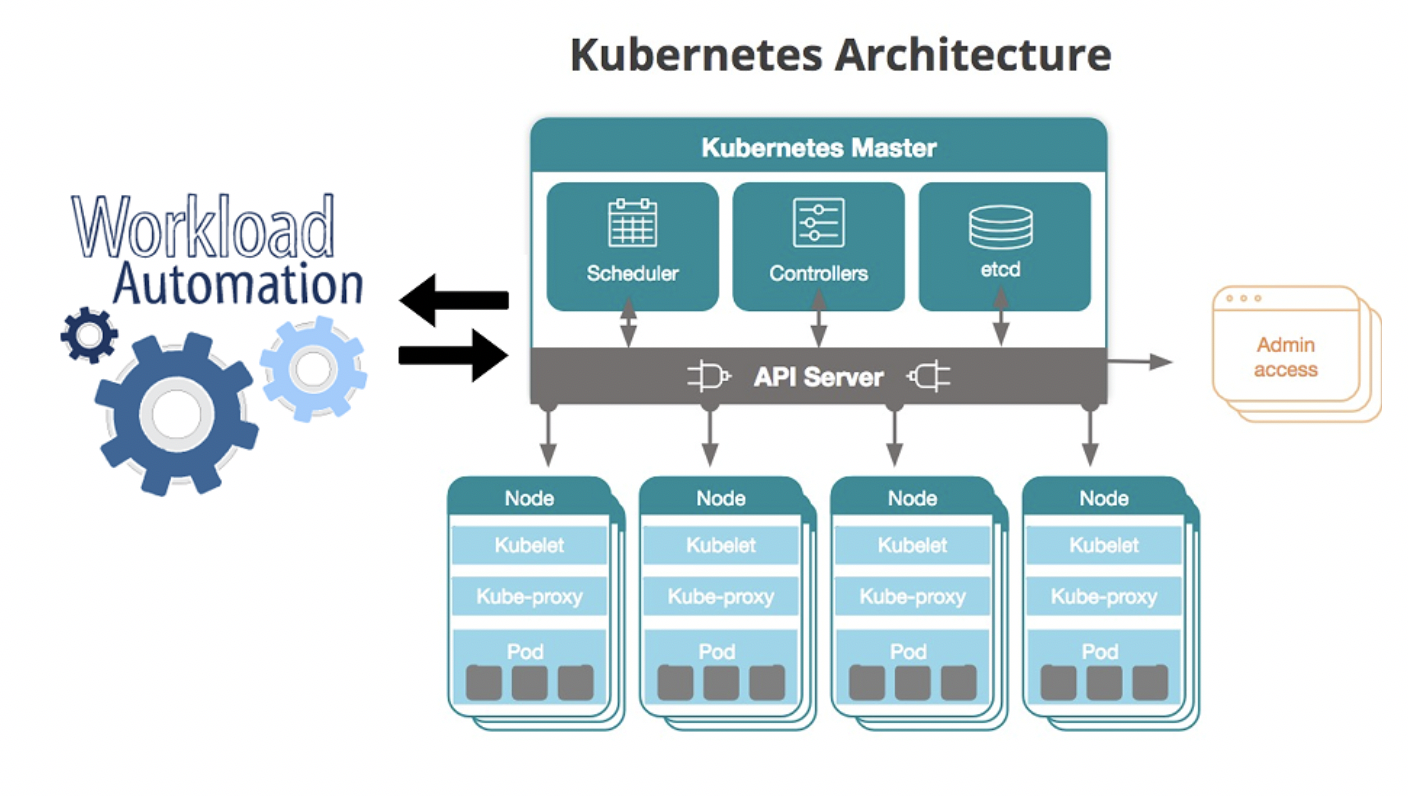
Kubernetes è disaccoppiato (o meglio, favorisce il disaccoppiamento).
Le astrazioni fornite in Kubernetes supportano naturalmente l'idea di servizi disaccoppiati che possono essere scalati e aggiornati in modo indipendente.
Questi servizi sono separati logicamente e comunicano tramite API ben definite.
Questa separazione logica consente ai team di implementare le modifiche nella produzione a una velocità maggiore poiché ogni servizio può operare su cicli di rilascio indipendenti (a condizione che rispettino i contratti API esistenti).
L'infrastruttura diventa immutabile.
Il significato di questo è molto importante. Piuttosto che entrare nell'istanza attiva per sostituire il software o una sua libreria, su Kubernetes andrai a creare una nuova versione del container, la installerai e terminerai la vecchia versione.
Di fatto questa procedura rende effimere le istanze, che sono a questo punto sempre pronte per essere create e distrutte.
Di cosa è fatto Kubernetes?

Kubernetes è sostanzialmente fatto di oggetti, che sono descritti da quelle che prima, parlando dello stato, chiamavo configurazioni (more or less).
Pod
Il Pod è l'oggetto fondamentale di Kubernetes, composto da uno o più container (strettamente correlati), uno strato di rete condiviso e volumi condivisi (filesystem, storage).
Analogamente ai container, i pod sono progettati per essere effimeri: non ci si aspetta che un singolo pod specifico persista per molto tempo.
Oh, i Pod consentono di eseguire vari container, ma non è consigliato. La best practice è 1 Pod == 1 Container.
Deployment
Un oggetto Deployment comprende una raccolta di pod definiti da un template e un certo numero di repliche (quante copie del template vogliamo eseguire).
Si può impostare un valore specifico per il count delle repliche o utilizzare una risorsa Kubernetes separata (ad es. un autoscaler orizzontale) per controllare il numero delle repliche in base a metriche di sistema come l'utilizzo della CPU.
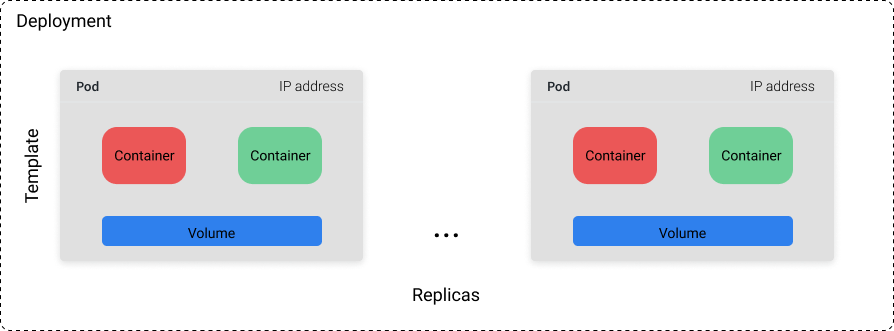
Anche se non si può fare affidamento che un pod rimanga in esecuzione indefinitamente, si può star certi che il cluster cercherà sempre di avere n pod disponibili (dove n è definito dal numero di repliche specificato).
Se abbiamo una distribuzione con un count di repliche pari a 10 e 3 di questi pod si bloccano a causa di un guasto, verranno pianificati altri 3 pod per essere eseguiti su una macchina diversa nel cluster.
Per questo motivo, i Deployment sono più adatti per applicazioni stateless in cui i pod possono essere sostituiti in qualsiasi momento senza rompere le cose.
Service
A ogni pod in Kubernetes viene assegnato un indirizzo IP univoco. Chiaramente ci serve per poter comunicare col software dentro al pod, altrimenti sarebbe us sistema isolato (e pressoché inutile).
MA! Poiché i pod sono effimeri, può essere parecchio difficile inviare traffico al container giusto.
È qui che l'oggetto Servizio entra in gioco.
Un Service su Kubernetes fornisce un endpoint stabile che può essere utilizzato per indirizzare il traffico ai pod giusti anche se gli esatti pod sottostanti cambiano a causa di aggiornamenti, ridimensionamento e errori.
I servizi sanno a quali pod devono inviare il traffico in base alle etichette (coppie chiave-valore) che definiamo nei metadati del pod.
Ingress
Mentre un servizio ci consente di esporre le applicazioni dietro un endpoint stabile, l'endpoint è disponibile solo per il traffico interno al cluster.
Se volessimo esporre la nostra applicazione al traffico esterno, dobbiamo definire un oggetto Ingress.
Il vantaggio è che puoi selezionare i Servizi da rendere pubblicamente disponibili.
Ad esempio, supponiamo che oltre al nostro servizio per un modello di machine learning, disponessimo di un'interfaccia utente che sfruttava le previsioni del modello come parte di un'applicazione più ampia.
Possiamo scegliere di rendere disponibile solo l'interfaccia utente al pubblico, impedendo agli utenti di interrogare direttamente il servizio del modello.
Job
Gli oggetti Kubernetes che ho descritto fino a questo punto possono essere composti per creare servizi affidabili e che girano a lungo.
Al contrario, l'oggetto Job è utile quando si desidera eseguire un'attività discreta.
I Job ci forniscono la possibilità di fare esattamente questo!
Se per qualche motivo il nostro container si arresta in modo anomalo prima di terminare lo script, Kubernetes reagirà lanciando un nuovo Pod al suo posto per completare il job.
Per gli oggetti Job, lo "stato desiderato" dell'oggetto è il completamento del job.
…and more
Chiaramente non li elenco tutti, questi sono solo i principali, altrimenti stiamo qui fino alla fine dei tempi.
- Volume
- per la gestione delle directory montate sui pod
- Secret
- per la memorizzazione di dati sensibili
- Namespace
- per separare le risorse sul cluster
- ConfigMap
- per specificare i valori di configurazione dell'applicazione da montare come file
- HorizontalPodAutoscaler
- per il ridimensionamento dei deployment in base all'utilizzo delle risorse dei pod esistenti
- StatefulSet
- simile a un deployment, ma per quando è necessario eseguire un'applicazione con stato
Quando non dovresti usare Kubernetes?
Come per ogni nuova tecnologia, dovrai impararlo "sul campo", e la curva di apprendimento potrebbe essere piuttosto ripida.
È lecito chiedersi "ho davvero bisogno di Kubernetes?", quindi ho pensato di raccogliere alcuni motivi per cui la risposta potrebbe essere "NO".
- Puoi eseguire il carico di lavoro su una singola macchina. (Kubernetes può essere visto come una piattaforma per la creazione di sistemi distribuiti, ma non dovresti creare un sistema distribuito se non ne hai bisogno!)
- Le tue esigenze di elaborazione sono leggere. (In questo caso, il calcolo speso per il framework di orchestrazione è relativamente alto!)
- Non hai bisogno di alta disponibilità e puoi tollerare tempi di inattività.
- Non prevedi di apportare molte modifiche ai servizi distribuiti.
- Hai già uno stack di strumenti efficace di cui sei soddisfatto.
- Hai un'architettura monolitica e non prevedi di separarla in microservizi. (Ciò risale a utilizzare lo strumento come era stato progettato per essere utilizzato.)
- Hai letto questa presentazione e hai pensato "porca puttana è complicato" piuttosto che "porca troia è utile".
Saluti
Grazie a tutti per essere arrivati fin qui!
